
The Fiduciary Diode: Engineering Neutrality in the Age of Slop
Better prompts. More sources. Stronger policies. Every obvious fix fails for the same reason.

Part 2 of a three-part series on Axiomatic Intelligence, a post-probabilistic architecture for the age of noise.
In Part 1, we diagnosed a disease. The internet has become hostile territory for anyone trying to make a purchase decision. SEO arbitrage floods the web with content optimized for algorithms, not humans. Marketing hallucination has made every product “best in class.” Affiliate corruption ensures that the loudest recommendations come from those with the most to gain from your purchase.
Then came Large Language Models. They trained on this polluted corpus and learned to reproduce it fluently. The result is what we called the Beige Singularity - the convergence of all AI output toward the statistical average of the internet. Confident. Comprehensive. Empty.
The diagnosis was clear: probability cannot distinguish signal from noise when noise is the majority. AI recommends products with the best marketing, not the best performance. It amplifies hype cycles. It hedges when it should warn. It produces what reads like expertise but functions like marketing.
That was the disease. Now we need the cure. The temptation is to reach for the obvious fixes. Better prompts. More sources. Smarter fact-checking. Stronger policies. Each solution sounds reasonable. Each one fails for the same structural reason.
The Graveyard of Fixes
Better Models Won’t Save Us

The first instinct is technological optimism: if current models produce pollution, future models will produce truth. This intuition is wrong. GPT-6 will not solve this. Neither will GPT-7. Each generation of frontier models makes the problem worse, not better. The prose becomes smoother. The citations look more plausible. The confidence becomes more assured. But the underlying epistemology remains unchanged: average the training corpus and predict the next token.
When the corpus is polluted, the average is polluted. Better models simply produce better-sounding pollution - fluent, confident, systematically biased toward whatever dominated their training data. The architecture cannot escape this trap because the architecture is the trap.
Consensus Is Not Truth
The second instinct reaches for crowd wisdom: if enough sources agree, the claim must be valid. This sounds democratic. It is mathematically wrong. Standard AI treats frequency as a proxy for validity. If most documents say Product X is excellent, the model concludes Product X is probably excellent. But consider the structure of information on the web. Marketing content is produced at industrial scale. It is optimized for discoverability. It dominates the corpus. Authentic user experience is scattered, unoptimized, and often buried. A probabilistic model trained on this distribution will reproduce its biases with perfect fidelity.
The problem becomes acute during product launches. For the first 90 days after any major release, the web floods with unboxing videos, first-impression reviews, and breathless coverage. This content is uniformly positive because negative experiences require time to accumulate. A system queried during this window returns confident recommendations based on a “consensus” that does not yet reflect reality. Six months later, the failure modes emerge - the battery degrading faster than expected, the software update breaking a critical feature, the hinge developing a wobble. But by then, the 90-day content has been indexed, ranked, and absorbed into training data. The early consensus has calcified into received wisdom.
Hype cycles manufacture artificial agreement. Marketing campaigns create the illusion of widespread satisfaction. A system that treats frequency as truth cannot detect - let alone correct - these distortions. It will recommend the product with the best marketing department, not the best engineering team.
Summarization Is Not Adjudication
The third instinct aims to synthesize: surely an AI that reads widely and summarizes carefully can separate signal from noise. This confuses two fundamentally different operations. Summarization averages. It finds the central tendency of a corpus and expresses it fluently. When you ask an AI for a product recommendation and receive a response citing “excellent reviews” and “strong performance,” you are receiving a summary of marketing materials weighted by their prevalence in training data. The model has faithfully learned the distribution and reproduced it. The distribution is wrong.
Adjudication litigates. It takes conflicting claims, examines evidence, and renders a verdict. When Reddit says “Buy” but return data shows 23% breakage rates within 30 days, adjudication does not average these signals. It resolves the conflict by examining which evidence is more trustworthy and concludes that transactional behavior outweighs stated opinions.
The obsessive researcher who spends 40 hours before a major purchase understands this distinction intuitively. They read the marketing materials - then hunt for the Reddit thread where a frustrated user explains the flaw that reviewers missed. They watch the teardown video. They find the obscure forum post from 2019 where an engineer explains why a particular design choice causes long-term reliability issues. They collide claims against reality and render a verdict. This is what AI must learn to do. Not to summarize more fluently, but to adjudicate more rigorously.
Policy Cannot Substitute for Architecture
The fourth instinct - and the most seductive - is governance: if economic incentives corrupt recommendations, we need stronger policies to prevent corruption. This misunderstands how systems work.
The structural problem with product recommendation is that the recommender is typically compensated by the seller. A “review” site that earns commission on purchases has a financial incentive to recommend products, not to warn against them. The more expensive the product, the higher the commission. No amount of policy commitment can overcome this economic pressure over time. A system that earns higher commissions for recommending expensive products will drift toward recommending expensive products - not through malice, but through the accumulated weight of thousands of micro-optimizations.
You cannot promise your way out of a structural conflict of interest. Trust cannot be promised. It must be verified. Policy is a commitment. Architecture is a constraint. A policy says “we won’t let revenue influence rankings.” Architecture makes the ranking system structurally incapable of seeing revenue data. The first requires trust. The second can be proven mathematically.
Every fix in this graveyard shares the same failure mode: it attempts to solve a structural problem through better execution of the existing paradigm. Better models. Better synthesis. Better policies. But when the paradigm itself is flawed - when probabilistic averaging cannot distinguish truth from noise - better execution produces better-looking failure. The solution is not better models. It is a different paradigm.
Borrowed Physics: Precedents from History
The problem we face is not new. The specific domain is novel, but the underlying challenge - how do you architect trust into a system where individual actors have incentives to deceive - has been solved before.
The Bookkeeper’s Dilemma

In 1494, a Franciscan friar named Luca Pacioli codified a system that Venetian merchants had been developing for decades: double-entry bookkeeping. Every transaction recorded twice - once as a debit, once as a credit. The totals must balance. If they don’t, something is wrong.
This sounds trivial. It wasn’t. Before double-entry, merchants kept single records of transactions. Errors accumulated. Fraud hid in the gaps. A dishonest bookkeeper could manipulate entries without detection. The merchant’s trust in their own books was a matter of faith, not verification.
Double-entry didn’t require merchants to be more honest. It made dishonesty structurally detectable. The system itself enforced integrity through mathematical constraint. If debits don’t equal credits, the error is visible - not through auditor intuition, but through arithmetic certainty. Five centuries later, the principle remains unchanged. Modern accounting still uses double-entry because the physics are sound: redundancy creates verification.
The Scientist’s Dilemma
Scientific peer review emerged from a similar recognition. Researchers have incentives to publish positive results. Journals have incentives to publish exciting findings. Left unchecked, these incentives produce a literature contaminated by false positives, unreplicable results, and fraud.
The solution was not to ask scientists to be more honest. It was to architect verification into the system. Peer review. Replication requirements. Statistical standards. Pre-registration of hypotheses. Each mechanism exists because the system cannot trust individual actors to police themselves.
Notice what both solutions share: they do not rely on good intentions. They assume conflicting incentives and architect around them. They build systems where dishonesty becomes detectable, not systems that ask for honesty.
This is the principle we must apply to AI recommendation. Not better prompts. Not stronger policies. Structural constraints that make corruption visible and verification automatic.
The Fiduciary Diode
Here is the architectural insight: separate the brain from the wallet. The structural problem with affiliate-funded recommendation is that the system that decides what to recommend is the same system that profits from the recommendation. This creates an unfixable conflict. No matter how strong the policy, the incentive gradient points toward corruption.
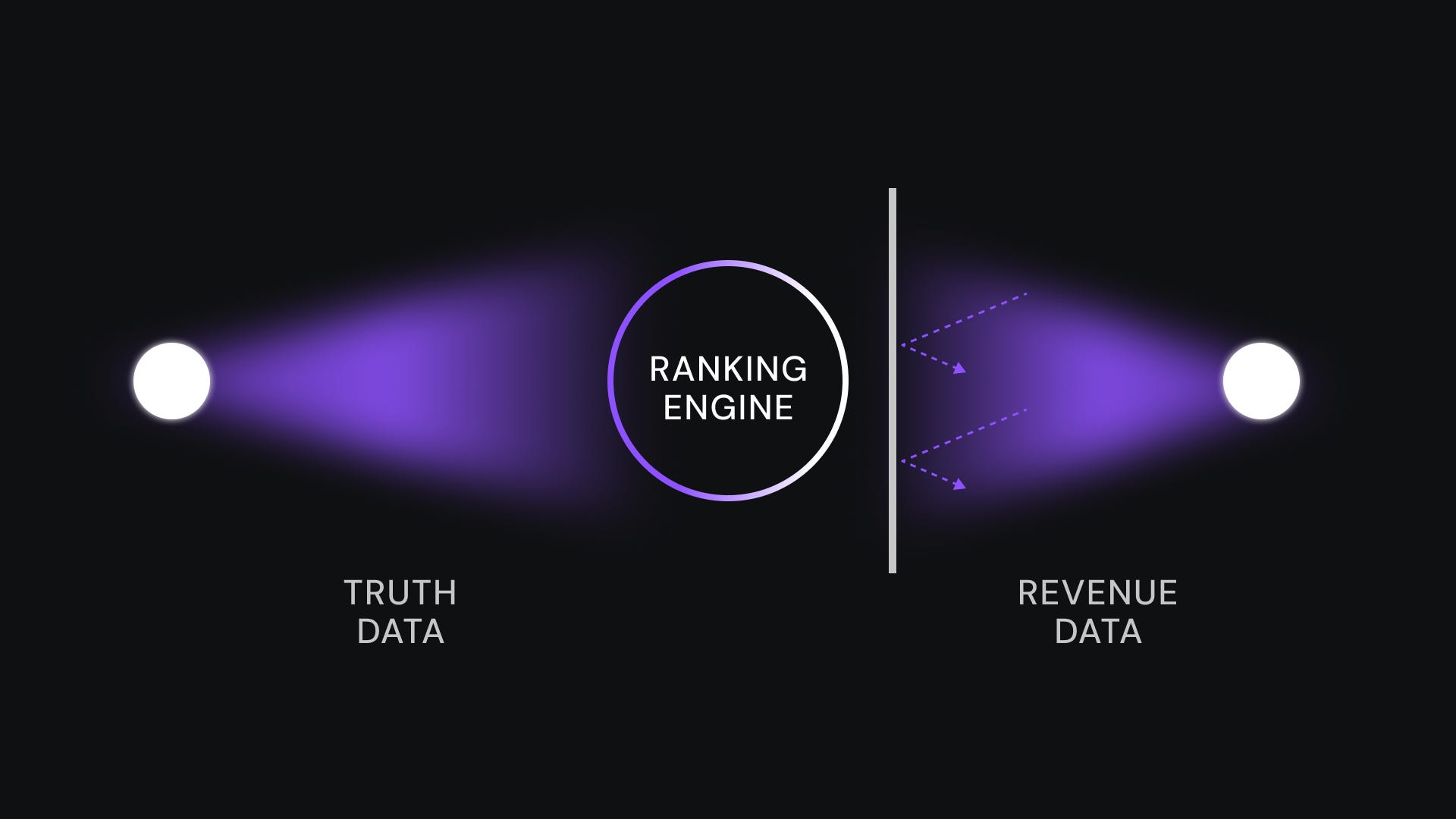
The solution is what we call the Fiduciary Diode - a one-way information barrier that makes it structurally impossible for revenue data to influence ranking decisions. The architecture works like this: the ranking engine reads from a database view that physically excludes commission data. It cannot see which products pay more. It cannot optimize for revenue because revenue is invisible to it. The ranking is based purely on truth metrics - verification scores, failure rates, user-reported problems, physical constraints.
A separate routing engine handles monetization. After the ranking is complete - after the verdict is rendered - the routing engine selects which affiliate link to use. It optimizes for revenue, but only among products that already passed the truth filter.
This is not a policy. It is a schema constraint. The ranking algorithm literally cannot see the money. You don’t have to trust us not to let revenue influence rankings. You can verify that the architecture makes it impossible. The diode only flows one way. Truth data flows up to ranking. Revenue data stays below, in routing. The wall between them is not a promise. It is code.
The Adversarial Reasoning Cycle
Architecture constrains. But architecture alone doesn’t generate truth. You still need a mechanism for converting polluted web data into verified claims. The key insight is that truth is not found. It is litigated. And litigation requires multiple witnesses with different perspectives.
We process four distinct types of evidence - what we call vectors - each designed to capture what the others miss:
The Marketer ingests official claims. Spec sheets. Marketing copy. Press releases. This is the thesis that must be tested. It contains real information about intended performance, but it is systematically optimistic.
The Scientist ingests objective measurements. Benchmark data. Lab test results. Teardown analyses. This vector grounds marketing claims in physical reality. If marketing says “10-hour battery” and lab tests show 6 hours, the Scientist captures that discrepancy.
The Crowd ingests lived experience. Reddit threads. YouTube comments. Forum discussions. This vector captures what specs cannot measure. A phone might have excellent benchmark scores but feel laggy in daily use. A shoe might meet every specification but cause blisters after two miles.
The Ore ingests proprietary transaction data that does not exist on the public web. Return rates. Cart abandonment patterns. Support conversations. This is the vector that cannot be gamed. A user who initiates a return paid money, received the product, used it, and decided it was not worth keeping. That is a costly signal.
These vectors are designed to conflict. We want contradiction. Contradiction is signal. When all four converge on the same conclusion, that convergence is evidence of truth. When they diverge, that divergence reveals the limits of our knowledge.
The process we use to force this conflict is called the Adversarial Reasoning Cycle. It operates in five phases:
Phase 1: Extract. We begin with a claim - typically a marketing claim or common belief. “The iPhone 17 has the best camera in a smartphone.”
Phase 2: Attack. We attack the claim from all four vectors simultaneously. The Marketer returns Apple’s official claims and benchmark citations. The Scientist returns DXOMark scores and independent lab tests. The Crowd returns Reddit sentiment and YouTube comment analysis. The Ore returns proprietary data on return rates and support conversations mentioning camera performance.
Phase 3: Collide. We force the vectors into direct conflict. “DXOMark scores support the claim.” “Reddit users report disappointing low-light performance.” “Return data shows camera cited in 12% of returns, 2x the category average.” “Marketing specifically references daylight photography.” These claims cannot all be true. The collision is the signal.
Phase 4: Synthesize. The collision reveals partial truth. The iPhone 17 excels in daylight photography (supported by benchmarks, consensus, and low daylight-related returns). It underperforms in low light relative to expectations (contradicted by user consensus and elevated return rates). The marketing claim is technically accurate but contextually misleading.
Phase 5: Produce. We generate what we call a Kinetic Axiom - a living truth object with confidence scores, evidence traces, and explicit mutation triggers. The axiom includes triggers for automatic re-verification: re-check on iOS update release, or if sentiment shift detected.
This is not summarization. It is litigation. The system does not average conflicting claims. It adjudicates them.
The Proof Packet
One problem remains. How do you know the system actually works as described? How do you verify that the Fiduciary Diode is enforced, that the adversarial cycle was actually executed, that the verdict wasn’t manipulated?
We require cryptographic auditability. Every recommendation generates what we call a Proof Packet - a signed log that demonstrates, verifiably, which data was visible during ranking, which evidence sources were consulted during reasoning, and what evidence supported the verdict. This is not a policy statement. It is a mathematical receipt.

If the Proof Packet shows that commission data was present during ranking - if the diode was bypassed - the ranking is invalid. This is the difference between “trust us” and “verify us.” The Proof Packet answers the question users have learned not to ask: “Why should I believe you?” Not because we promise neutrality. Because we prove it for every recommendation, and the proof is auditable.
What This Looks Like in Practice
Theory matters less than experience. Here’s the difference between what exists today and what becomes possible:
Current State: The Probabilistic Response
You ask: “I want to buy an espresso machine under $500.”
The AI responds: “The Breville Barista Express is widely considered one of the best espresso machines in its price range. It features a built-in grinder, 15-bar Italian pump, and precise temperature control. The De’Longhi La Specialista is another excellent option with a smart tamping system...”
This is fluent marketing synthesis. It tells you nothing about failure modes. It doesn’t mention that the Breville’s steam wand is reported to clog frequently if not cleaned daily. It doesn’t mention that the De’Longhi has documented pressure consistency issues after 18 months. It regurgitates what dominates the training corpus: promotional content.
Axiomatic State: The Adjudicated Verdict
Same question. Different architecture. The system responds: “For espresso under $500, I need to ask: How important is milk steaming versus straight espresso? And do you have space for a machine with a built-in grinder?”
You answer: “Milk drinks daily. Limited counter space.”
Verdict: “The Breville Barista Express appears in every ‘best of’ list, but our analysis flags a concern: user forums and return data both show elevated complaints about the steam wand clogging, specifically for daily milk drink users. Cleaning requirements are higher than competitors - miss a day, and you’re descaling. For your use case, the Gaggia Classic Pro with a separate grinder outperforms despite the lower ‘review score.’ Return rates for daily milk drink users are 40% lower than the Breville. Trade-off: you lose the integrated grinder convenience. Based on your space constraints and usage pattern, the Gaggia is the recommended option with high confidence.”
The difference isn’t tone. It’s epistemology. The first response tells you what’s popular. The second tells you what’s true - for you, specifically - and shows the evidence.
The Invitation
We are building this architecture. The principles are described in detail in our technical whitepaper, available on GitHub.
But principles are only the beginning. The system must be built, category by category, verdict by verdict. It requires adversarial verification at scale, epistemic type classification, confidence calibration, signal-gated re-verification, and infrastructure that doesn’t exist yet.
In Part 3, we’ll examine what this means for the broader landscape: how agents proliferating across devices and platforms will need sources of verified truth, and what happens to an economy when AI can adjudicate rather than merely summarize.
The Beige Singularity is not inevitable. It is a consequence of a paradigm. Change the paradigm, and different outcomes become possible.
The description of the 'Beige Singularity' is a brilliant follow-up to the 'disease' diagnosis in Part 1. How do you foresee this neutrality engineering impacting the broader information ecosystem beyond product recomendations?